Building a personal, private AI computer on a budget
As everyone is well aware, the world is still going nuts trying to develop more, newer and better AI tools. Mostly by throwing absurd amounts of money at the problem. Many of those billions go towards building cheap or free services that operate at a significant loss. The tech giants that run them all are hoping to attract as many users as possible, so that they can capture the market, and become the dominant or only party that can offer them. It is the classic Silicon Valley playbook. Once dominance is reached, expect the enshittification to begin.
A likely way to earn back all that money for developing these LLMs will be by tweaking their outputs to the liking of whoever pays the most. An example of what that such tweaking looks like is the refusal of DeepSeek's R1 to discuss what happened at Tiananmen Square in 1989. That one is obviously politically motivated, but ad-funded services won't exactly be fun either. In the future, I fully expect to be able to have a frank and honest discussion about the Tiananmen events with an American AI agent, but the only one I can afford will have assumed the persona of Father Christmas who, while holding a can of Coca-Cola, will intersperse the recounting of the tragic events with a joyful "Ho ho ho... Didn't you know? The holidays are coming!"
Or maybe that is too far-fetched. Right now, dispite all that money, the most popular service for code completion still has trouble working with a couple of simple words, despite them being present in every dictionary. There must be a bug in the "free speech", or something.
But there is hope. One of the tricks of an upcoming player to shake up the market, is to undercut the incumbents by releasing their model for free, under a permissive license. This is what DeepSeek just did with their DeepSeek-R1. Google did it earlier with the Gemma models, as did Meta with Llama. We can download these models ourselves and run them on our own hardware. Better yet, people can take these models and scrub the biases from them. And we can download those scrubbed models and run those on our own hardware. And then we can finally have some truly useful LLMs.
That hardware can be a hurdle, though. There are two options to choose from if you want to run an LLM locally. You can get a big, powerful video card from Nvidia, or you can buy an Apple. Either is expensive. The main spec that indicates how well an LLM will perform is the amount of memory available. VRAM in the case of GPUs, normal RAM in the case of Apples. Bigger is better here. More RAM means bigger models, which will dramatically improve the quality of the output. Personally, I'd say one needs at least over 24GB to be able to run anything useful. That will fit a 32 billion parameter model with a little headroom to spare. Building, or buying, a workstation that is equipped to handle that can easily cost thousands of euros.
So what to do, if you don't have that amount of money to spare? You buy second-hand! This is a viable option, but as always, there is no such thing as a free lunch. Memory may be the primary concern, but don't underestimate the importance of memory bandwidth and other specs. Older equipment will have lower performance on those aspects. But let's not worry too much about that now. I am interested in building something that at least can run the LLMs in a usable way. Sure, the latest Nvidia card might do it faster, but the point is to be able to do it at all. Powerful online models can be nice, but one should at the very least have the option to switch to a local one, if the situation calls for it.
Below is my attempt to build such a capable AI computer without spending too much. I ended up with a workstation with 48GB of VRAM that cost me around 1700 euros. I could have done it for less. For instance, it was not strictly necessary to buy a brand new dummy GPU (see below), or I could have found someone that would 3D print the cooling fan shroud for me, instead of shipping a ready-made one from a faraway country. I'll admit, I got a bit impatient at the end when I found out I had to buy yet another part to make this work. For me, this was an acceptable tradeoff.
Hardware
This is the full cost breakdown:
| Part | Price | |
|---|---|---|
| 2 x Nvidia Tesla P40 | € 659,98 | GPUs |
| HP Z440 Workstation | € 568,50 | I already owned this |
| NZXT C850 Gold | € 135,17 | Power supply |
| Gainward GT 1030 | € 108,75 | Dummy GPU |
| Nvidia Tesla Cooling Fan Kit | € 98,51 | Including shipping |
| MODDIY Main Power Adaptor Cable | € 39,99 | HP sucks |
| Akasa Multifan Adapter | € 5,05 | For the GPU fans |
| Total | € 1695.15 |
And this is what it looked liked when it first booted up with all the parts installed:

I'll give some context on the parts below, and after that, I'll run a few quick tests to get some numbers on the performance.
HP Z440 Workstation
The Z440 was an easy pick because I already owned it. This was the starting point. About two years ago, I wanted a computer that could serve as a host for my virtual machines. The Z440 has a Xeon processor with 12 cores, and this one sports 128GB of RAM. Many threads and a lot of memory, that should work for hosting VMs. I bought it secondhand and then swapped the 512GB hard drive for a 6TB one to store those virtual machines. 6TB is not required for running LLMs, and therefore I did not include it in the breakdown. But if you plan to collect many models, 512GB might not be enough.
I have come to like this workstation. It feels all very solid, and I haven't had any problems with it. At least, until I started this project. It turns out that HP does not like competition, and I encountered some difficulties when swapping components.
2 x NVIDIA Tesla P40
This is the magic ingredient. GPUs are expensive. But, as with the HP Z440, often one can find older equipment, that used to be top of the line and is still very capable, second-hand, for relatively little money. These Teslas were meant to run in server farms, for things like 3D rendering and other graphic processing. They come equipped with 24GB of VRAM. Nice. They fit in a PCI-Express 3.0 x16 slot. The Z440 has two of those, so we buy two. Now we have 48GB of VRAM. Double nice.
The catch is the part about that they were meant for servers. They will work fine in the PCIe slots of a normal workstation, but in servers the cooling is managed differently. Beefy GPUs consume a lot of power and can run very hot. That is the reason consumer GPUs always come equipped with big fans. The cards need to take care of their own cooling. The Teslas, however, have no fans whatsoever. They get just as hot, but expect the server to supply a steady flow of air to cool them. The enclosure of the card is somewhat shaped like a pipe, and you have two options: blow in air from one side or blow it in from the other side. How is that for flexibility? You absolutely must blow some air into it, though, or you will damage it as soon as you put it to work.
The solution is simple: just mount a fan on one end of the pipe. And indeed, it seems a whole cottage industry has grown of people that sell 3D-printed shrouds that hold a standard 60mm fan in just the right place. The problem is, the cards themselves are already quite bulky, and it is not easy to find a configuration that fits two cards and two fan mounts in the computer case. The seller who sold me my two Teslas was kind enough to include two fans with shrouds, but there was no way I could fit all of those into the case. So what do we do? We buy more parts.
NZXT C850 Gold
This is where things got annoying. The HP Z440 had a 700 Watt PSU, which might have been enough. But I wasn't sure, and I needed to buy a new PSU anyway because it did not have the right connectors to power the Teslas. Using this handy website, I deduced that 850 Watt would be sufficient, and I bought the NZXT C850. It is a modular PSU, meaning that you only need to plug in the cables that you actually need. It came with a neat bag to store the spare cables. One day, I might give it a good cleaning and use it as a toiletry bag.
Unfortunately, HP does not like things that are not HP, so they made it difficult to swap the PSU. It does not fit physically, and they also changed the main board and CPU connectors. All PSUs I have ever seen in my life are rectangular boxes. The HP PSU also is a rectangular box, but with a cutout, making sure that none of the normal PSUs will fit. For no technical reason at all. This is just to mess with you.
The mounting was eventually solved by using two random holes in the grill that I somehow managed to align with the screw holes on the NZXT. It sort of hangs stable now, and I feel lucky that this worked. I have seen Youtube videos where people resorted to double-sided tape.
The connector required... another purchase.

Not cool HP.
Gainward GT 1030
There is another issue with using server GPUs in this consumer workstation. The Teslas are intended to crunch numbers, not to play video games with. Consequently, they don't have any ports to connect a monitor to. The BIOS of the HP Z440 does not like this. It refuses to boot if there is no way to output a video signal. This computer will run headless, but we have no other choice. We have to get a third video card, that we don't to intent to use ever, just to keep the BIOS happy.
This can be the most scrappy card that you can find, of course, but there is a requirement: we must make it fit on the main board. The Teslas are bulky and fill the two PCIe 3.0 x16 slots. The only slots left that can physically hold a card are one PCIe x4 slot and one PCIe x8 slot. See this website for some background on what those names mean. One cannot buy any x8 card, though, because often even when a GPU is advertised as x8, the actual connector on it might be just as wide as an x16. Electronically it is an x8, physically it is an x16. That won't work on this main board, we really need the small connector.
Nvidia Tesla Cooling Fan Kit
As said, the challenge is to find a fan shroud that fits in the case. After some searching, I found this kit on Ebay an bought two of them. They came delivered complete with a 40mm fan, and it all fits perfectly.
Be warned that they make an awful lot of noise. You don't want to keep a computer with these fans under your desk.
To keep an eye on the temperature, I whipped up this quick script and put it in a cron job. It periodically reads out the temperature on the GPUs and sends that to my Homeassistant server:
#!/bin/bash
# Configuration
HA_URL="http://localhost:8123"
TOKEN="<your_long_lived_access_token>"
# Function to send data to HA sensor
send_to_ha() {
local gpu_id=$1
local temp=$2
# Define the payload for the REST API call
PAYLOAD='{"state": "'"$temp"'"}'
# Send POST request to update the state of a sensor entity in HA
curl -X POST \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
"$HA_URL/api/states/sensor.gpu_${gpu_id}_temp" \
--data "$PAYLOAD"
}
# Get GPU temperatures using nvidia-smi and send them to HA
nvidia-smi -q | grep 'GPU Current Temp' | awk '{print $5}' | while read -r temp; do
# Assuming GPUs are indexed from 0 upwards
gpu_id=$(($gpu_id + 1))
if [ "$temp" ]; then
send_to_ha $(($gpu_id - 1)) "$temp"
fi
done
# Reset GPU index counter (optional)
unset gpu_id
In Homeassistant I added a graph to the dashboard that displays the values over time:
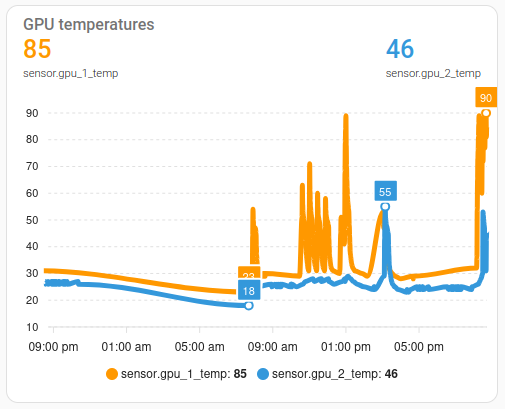
As one can see, the fans were noisy, but not particularly effective. 90 degrees is far too hot. I searched the internet for a reasonable upper limit but could not find anything specific. The documentation on the Nvidia site mentions a temperature of 47 degrees Celsius. But, what they mean by that is the temperature of the ambient air surrounding the GPU, not the measured value on the chip. You know, the number that actually is reported. Thanks, Nvidia. That was helpful.
After some further searching and reading the opinions of my fellow internet citizens, my guess is that things will be fine, provided that we keep it in the lower 70s. But don't quote me on that.
My first attempt to remedy the situation was by setting a maximum to the power consumption of the GPUs. According to this Reddit thread, one can lower the power consumption of the cards by 45% at the cost of only 15% of the performance. I tried it and... did not notice any difference at all. I wasn't sure about the drop in performance, having only a couple of minutes of experience with this configuration at that point, but the temperature characteristics were definitely unchanged.
And then a light bulb flashed on in my head. You see, just before the GPU fans, there is a fan in the HP Z440 case. In the photo above, it is in the right corner, inside the black box. This is a fan that sucks air into the case, and I figured this would work in tandem with the GPU fans that blow air into the Teslas. But this case fan was not spinning at all, because the rest of the computer did not need any cooling. Looking into the BIOS, I found a setting for the minimum idle speed of the case fans. It ranged from 0 to 6 stars and was currently set to 0. Putting it at a higher setting did wonders for the temperature. It also made more noise.
I'll reluctantly admit that the third video card was helpful when adjusting the BIOS setting.
MODDIY Main Power Adaptor Cable and Akasa Multifan Adaptor
Fortunately, sometimes things just work. These two items were plug and play. The MODDIY adaptor cable connected the PSU to the main board and CPU power sockets.
I used the Akasa to power the GPU fans from a 4-pin Molex. It has the nice feature that it can power two fans with 12V and two with 5V. The latter obviously reduces the speed and thus the cooling power of the fan. But it also reduces noise. Fiddling a bit with this and the case fan setting, I found an acceptable tradeoff between noise and temperature. For now at least. Maybe I will need to revisit this in the summer.
Some numbers
Inference speed. I collected these numbers by running ollama with the --verbose flag and asking it five times to write a story and averaging the result:
$ ollama run gemma2:27b --verbose
>>> Can you write me a story about a tortoise and a hare, but one
that involves a race to get the most tokens per second?
Performancewise, ollama is configured with:
OLLAMA_FLASH_ATTENTION=1
OLLAMA_KV_CACHE_TYPE=q8_0
All models have the default quantization that ollama will pull for you if you don't specify anything.
| Model | Max power | Tokens per second |
|---|---|---|
| mistral-small:24b | 250W | 15.23 |
| mistral-small:24b | 140W | 13.95 |
| gemma2:27b | 250W | 13.90 |
| gemma2:27b | 140W | 13.50 |
| qwen2.5-coder:32b | 250W | 10.75 |
| qwen2.5-coder:32b | 140W | 10.60 |
| llama3.3:70b | 250W | 5.35 |
| llama3.3:70b | 140W | 5.00 |
| deepseek-r1:70b | 250W | 5.30 |
| deepseek-r1:70b | 140W | 4.94 |
Another important finding: Terry is by far the most popular name for a tortoise, followed by Turbo and Toby. Harry is a favorite for hares. All LLMs are loving alliteration.
Power consumption
Over the days I kept an eye on the power consumption of the workstation:
| State | Power |
|---|---|
| Idle | 80W |
| 32b model loaded | 123W |
| 32b model working | 241W |
| 70b model loaded | 166W |
| 70b model working | 293W |
Note that these numbers were taken with the 140W power cap active.
As one can see, there is another tradeoff to be made. Keeping the model on the card improves latency, but consumes more power. My current setup is to have two models loaded, one for coding, the other for generic text processing, and keep them on the GPU for up to an hour after last use.
Conclusion
After all that, am I happy that I started this project? Yes, I think I am.
I spent a bit more money than planned, but I got what I wanted: a way of locally running medium-sized models, completely under my own control.
It was a good choice to start with the workstation I already owned, and see how far I could come with that. If I had started with a new machine from scratch, it definitely would have cost me more. It would have taken me much longer too, as there would have been many more options to choose from. I would also have been very tempted to follow the hype and buy the latest and greatest of everything. New and shiny toys are fun. But if I buy something new, I want it to last for years. Confidently predicting where AI will go in 5 years time is impossible right now, so having a cheaper machine, that will last at least some while, feels satisfactory to me.
I wish you good luck on your own AI journey. I'll report back if I find something new or interesting.
Note: this post gathered some comments on Hackernews and lobste.rs with interesting insights. Be sure to check those out too if you're interested in building or buying a setup for local AI.